Databases
Author: Shine ChangDatabases
Database Schema
A file describing the format and types of data stored. This can range from a scratch file serving just as a developer’s note, or a strictly formatted file used by the database scripts.
- Entity Relationship Diagram A diagramming style to help with database design
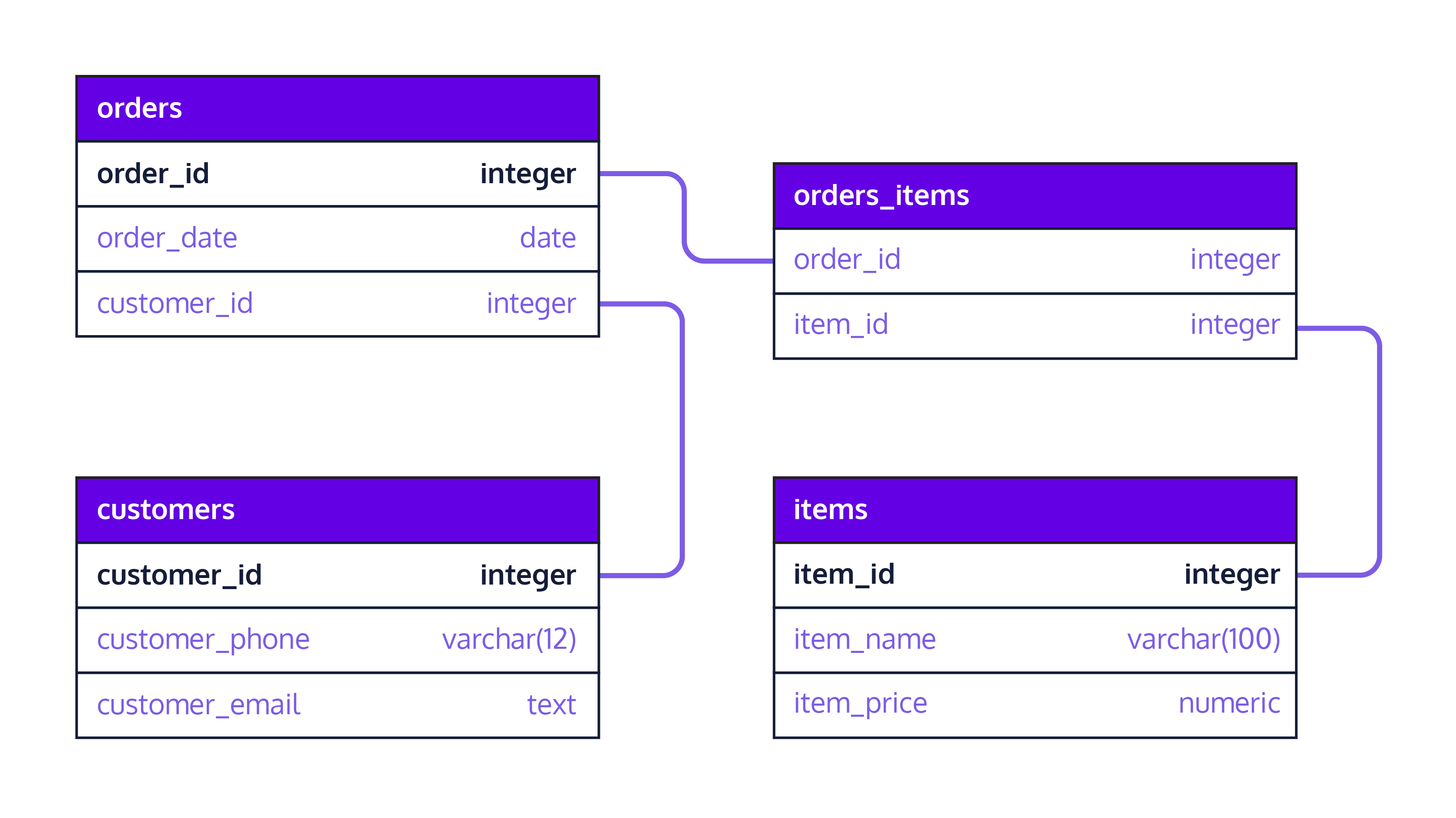
Types:
NoSQL/Document Oriented:
- Each entry (“document”) is effectively a javascript object.
- Document based databases do not require or enforce a schematic.
- Flexible & Easy to use (especially with Node.js).
- The more common type used by database servers / hosters.
SQL/Relational:
- A database is a collection of tables, analogous for collections.
- Each row is an entry in the table, and each column of a table represents a parameter in the collection. The columns must be a sized data type, meaning no objects or arrays can be stored within a table cell.
- The schematic defines the columns in each table, and the data type stored.
- A parameter in an entry can be related to another entry, for example via IDs. Refer to the image above for an example.
- To access (“query”) the database, SQL (Structured Query Language) is used. This is necessary to make it easier to query by database relations.
Example Query:
SELECT id, lon, lat FROM city
WHERE lat > 12.0 AND
lat < 14.1 AND
lon > 32.0 AND
lon < 64.5
ORDER BY population DESCGets the
id,lon,latcolumns of all rows from tablecity, wherelatandlonare in a certain range, sorted by population in descending order.
- A good database schematic / design is essential to reduce query overhead. A good database typically follows a few rules; these are called ”database normalization rules,” which we will go over later.
- Very powerful, but a bit inconvenient.
- AWS Article on SQL
Database Normalization
A set of rules and guidelines to grade a database schematic against. Typically, the more “normalization rules” your schematic satisfies, the “better” it is. By satisfying normal rule N, the schematic is in the Nth normal form. Microsoft Article on normalization
Database Clustering
Database Clustering is when multiple database servers exist to host a single database. This offloads traffic from a single server, improves scalability, provides fault tolerance, and also decreases latency with distributed servers. Two common solutions for offloading database traffic from a single server are replication and sharding.
Replication is done by having replicas of the database distributed in different regions. The secondary replicas can only handle read requests, and will forward any write requests to the primary set. This offloads the read traffic, which should be greater than write, and also provides back-up databases.
Sharding is when a single table or dataset is split and hosted by multiple servers. This reduces response time for both reading and writing, by eliminating the single bottleneck server.
Some database providers may implement these techniques out-of-the-box. For example, MongoDB has auto replication enabled.
Database Options
SQL/Relational
MySQL: Oracle’s SQL database service
Cloud SQL: Google’s SQL database hosting service. Free initial credits
Azure SQL: Microsoft’s SQL database hosting service. Free initial credits
SQLite: stores an SQL database locally. Good for amateur development. Local hosting, so, free.
NoSQL/Document-oriented
MongoDB Atlas: Real-time Database hosting service. Nice interface, clear documentation, simple syntax. Free.
Firebase RTDB: Real-time Database hosting. Good interface, terrible documentation. Iffy syntax as a result of not being able to find the cleanest way to implement something due to the poor documentation. Free.